Introduction to Deep Learning for Text with PyTorch
Text processing pipeline

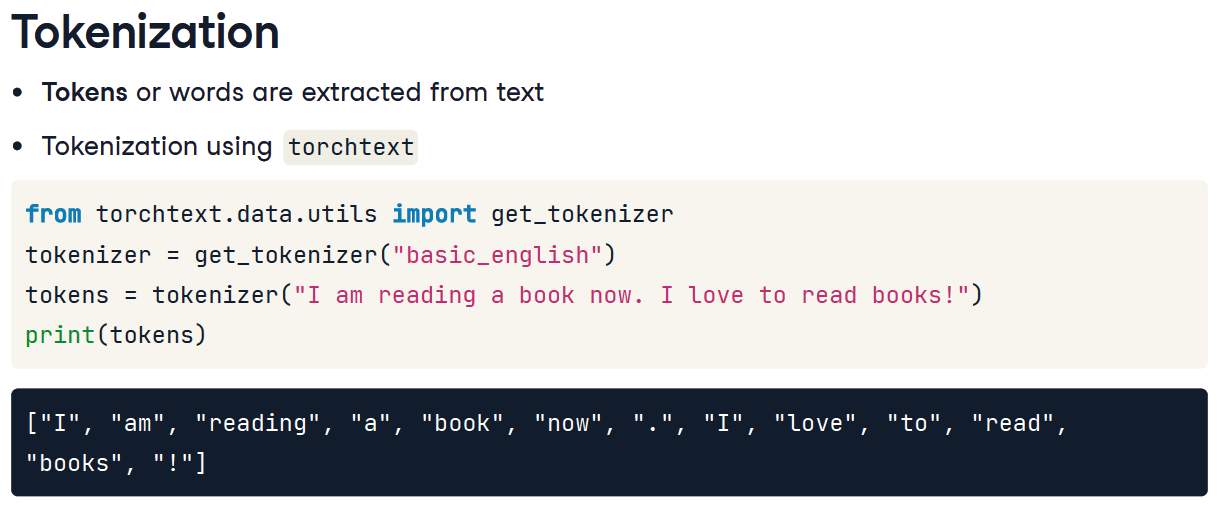
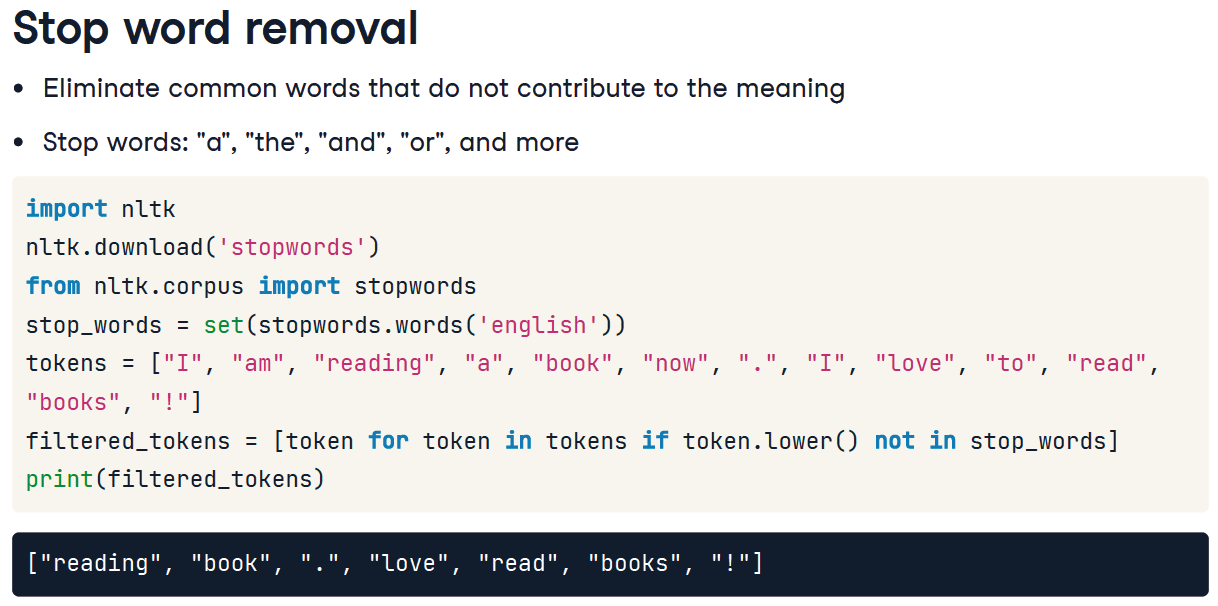
Preprocessing 단계
- Tokenization
- Stop word removing
- Stemming
- Rare word Removing


Encoding 단계
- One-hot Encoding : 1 only one dim, 0 others
- Bag of Words(BoW) : captures word frequency, disregarding order {'the': 2, 'cat': 1, 'sat': 1, 'on': 1, 'mat': 1}
- TF-IDF : Term Frequency-Inverse Document Frequency, balances uniqueness and importance
- Embedding : converts words into vectors, capturing semantic meaning




Pipelines
# Define your Dataset class
class ShakespeareDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# Create a list of stopwords
stop_words = set(stopwords.words("english"))
# Initialize the tokenizer and stemmer
tokenizer = get_tokenizer("basic_english")
stemmer = PorterStemmer()
# Complete the function to preprocess sentences
def preprocess_sentences(sentences):
processed_sentences = []
for sentence in sentences:
sentence = sentence.lower()
tokens = tokenizer(sentence)
tokens = [token for token in tokens if token not in stop_words]
tokens = [stemmer.stem(token) for token in tokens]
processed_sentences.append(' '.join(tokens))
return processed_sentences
processed_shakespeare = preprocess_sentences(shakespeare)
print(processed_shakespeare[:5])
# Complete the encoding function
def encode_sentences(sentences):
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(sentences)
return X.toarray(), vectorizer
# Complete the text processing pipeline
def text_processing_pipeline(sentences):
processed_sentences = preprocess_sentences(sentences)
encoded_sentences, vectorizer = encode_sentences(processed_sentences)
dataset = ShakespeareDataset(encoded_sentences)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
return dataloader, vectorizer
dataloader, vectorizer = text_processing_pipeline(processed_shakespeare)
# Print the vectorizer's feature names and the first 10 components of the first item
print(vectorizer.get_feature_names_out()[:10])
print(next(iter(dataloader))[0, :10])



