Sequences & Recurrent Neural Networks

import numpy as np
def create_sequences(df, seq_length):
xs, ys = [], []
# Iterate over data indices
for i in range(len(df) - seq_length):
# Define inputs
x = df.iloc[i:(i+seq_length), 1]
# Define target
y = df.iloc[i+seq_length, 1]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)for문의 range : len(df) - seq_length까지만 진행되므로 반드시 seq_length 이상의 길이는 보존됨
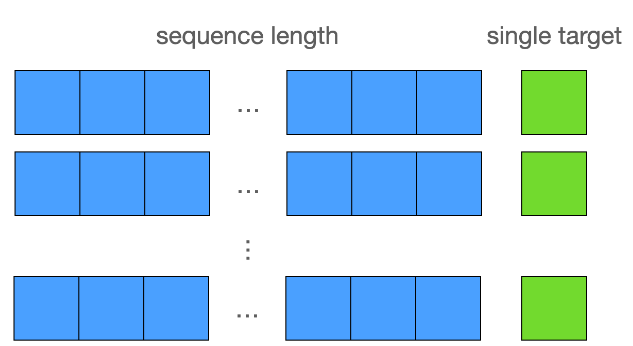
Sequential Dataset
import torch
from torch.utils.data import TensorDataset
# Use create_sequences to create inputs and targets
X_train, y_train = create_sequences(train_data, seq_length=96)
print(X_train.shape, y_train.shape)
# Create TensorDataset
dataset_train = TensorDataset(
torch.from_numpy(X_train),
torch.from_numpy(y_train),
)
print(len(dataset_train))RNN(Recurrent Neural Network)
이전 cell에서의 hidden representation이 다음 cell에서도 사용된다.
쉽게 말해 이전 정보를 "기억"한다
그치만 그 기억을 오래 못 갖고 있기 때문에, 바로 뒤에 새로운거 등장 예정

class Net(nn.Module):
def __init__(self):
super().__init__()
# Define RNN layer
self.rnn = nn.RNN(
input_size=1,
hidden_size=32,
num_layers=2,
batch_first=True,
)
self.fc = nn.Linear(32, 1)
def forward(self, x):
# Initialize first hidden state with zeros
h0 = torch.zeros(2, x.size(0), 32)
# Pass x and h0 through recurrent layer
out, _ = self.rnn(x, h0)
# Pass recurrent layer's last output through linear layer
out = self.fc(out[:, -1, :])
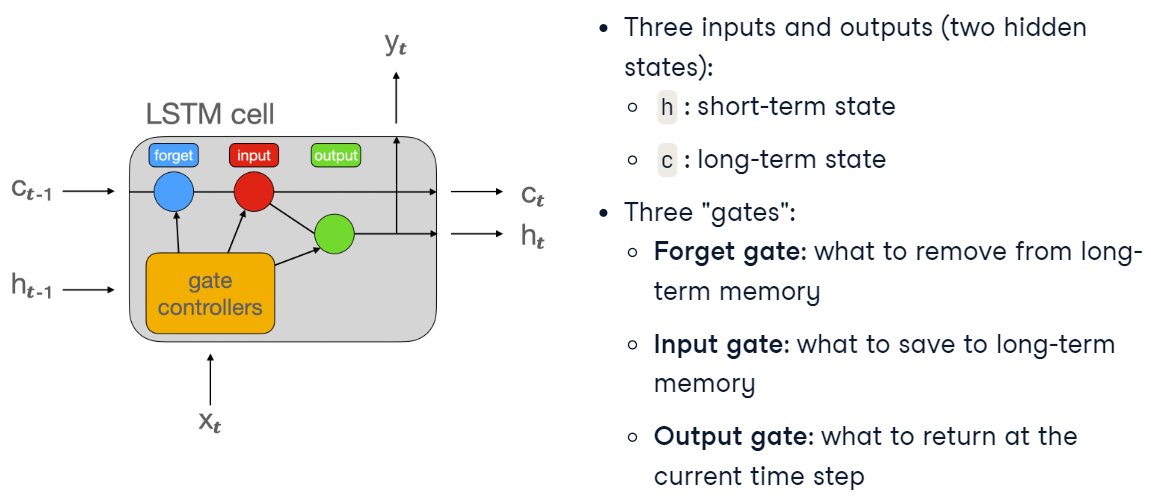
return outLSTM and GRU
class Net(nn.Module):
def __init__(self, input_size):
super().__init__()
# Define lstm layer
self.lstm = nn.LSTM(
input_size=1,
hidden_size=32,
num_layers=2,
batch_first=True,
)
self.fc = nn.Linear(32, 1)
def forward(self, x):
h0 = torch.zeros(2, x.size(0), 32)
# Initialize long-term memory
c0 = torch.zeros(2, x.size(0), 32)
# Pass all inputs to lstm layer
out, _ = self.lstm(x,(h0,c0))
out = self.fc(out[:, -1, :])
return out
class Net(nn.Module):
def __init__(self):
super().__init__()
# Define RNN layer
self.GRU = nn.GRU(
input_size=1,
hidden_size=32,
num_layers=2,
batch_first=True,
)
self.fc = nn.Linear(32, 1)
def forward(self, x):
h0 = torch.zeros(2, x.size(0), 32)
out, _ = self.gru(x, h0)
out = self.fc(out[:, -1, :])
return outLSTM과 GRU의 코드 자체는 크게 다를 건 없음
nn.GRU로 바꾸어주고, LSTM에서 있던 cell state(C0)없애주면 끝
GRU가 computation cost가 조금 더 적긴 하지만, 상황by상황으로 선택해야 됨
Training and Evaluating RNNs


Training Loop
net = Net()
# Set up MSE loss
criterion = nn.MSELoss()
optimizer = optim.Adam(
net.parameters(), lr=0.0001
)
for epoch in range(3):
for seqs, labels in dataloader_train:
# Reshape model inputs
seqs = seqs.view(16,96,1)
# Get model outputs
outputs = net(seqs)
# Compute loss
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
Evaluation Loop
# Define MSE metric
mse = torchmetrics.MeanSquaredError()
net.eval()
with torch.no_grad():
for seqs, labels in dataloader_test:
seqs = seqs.view(32, 96, 1)
# Pass seqs to net and squeeze the result
outputs = net(seqs).squeeze()
mse(outputs, labels)
# Compute final metric value
test_mse = mse.compute()
print(f"Test MSE: {test_mse}")


