논문을 읽거나 모델관련 공부를 하면, 실험 마지막엔 항상 성능을 평가하는데, 정작 지표를 잘 몰라서 "아 성능이 좋구나" 정도만 읽고 넘어갔다. 이번 기회에 분류성능평가지표에 대해 알아보려 한다.

- True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답~)
- False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답~)
- False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답~)
- True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답~)
precision, Recall, Accuracy
이해를 위해 한 달동안 수신한 메일이 스팸 or not을 예측하는 상황을 가정하자
precision
정밀도(precision)이란 모델이 True로 예측한 것중 실제로 True인 것의 비율이다

Positive 정답률, PPV(Positive Predictive Value)라고도 불린다. 스팸 분류기가 True라고 분류한 것중 실제로 True인지를 살펴보는 지표이다.
recall
재현률(recall)이란 실제로 True인 것중 모델이 True로 예측한 것의 비율이다
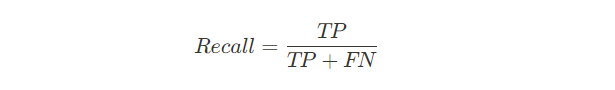
precision과 recall은 모두 모델이 True인 정답에 대해 True를 에측하는 것에 관심이 있다. 그런데 왜 지표가 두 개일까?
그 관점이 다르다.
Precision은 모델의 관점에서, recall은 실제 정답(data)의 입장에서 모델이 맞춘 정답이 궁금한 것이다.
각각의 분모를 보면, precision은 "모델이 True라고 예측한 값들", recall은 "실제 정답이 True인 것들"이기 떄문이다.
Suppose situation
어떤 조건에 의해서, 확실히 Spam으로 분류할 수 있는 메일이라면 그 메일은 Spam이라고 예측하면 되겠다
이 경우 확실치 않은 메일에 대해서는 예측을 보류함 → FP의 경우의 수를 줄여 Precision을 높이는 편법
Example) 30개의 메일 중 Spam은 20개인데, 어떤 조건에 의해 확실한 Spam 2개만 예측했다면 precision 100%임
이게 좋은 모델일 수가 없잖아 겉보기 훌륭 모델인거지
그래서, 20개의 spam메일 중에서 실제로 spam으로 예측된 것들(recall)을 고려해야함!! 이건 절대 precision만큼의 결과가 나올 수 없겠지 → Recall을 고려해야 실제 data의 입장에서 모델의 예측을 평가할 수 있음 → precision과 recall은 함께 고려되어야 하며 상호보완적이고, 둘 다 높으면 모델 성능이 좋음
Precision-Recall Trade-off



type1error, type2error에 대한 critical region을 설정해서, 그 영역 안에서 뽑히는건 error이다. 그림에선 Any mean이 기준인데, 기준선을 보면 알겠지만 선이 옮겨다님에 따라 양쪽 영역이 모두 커질 수는 없고, 하나가 커지면 하나가 작아지는 상호보완적인 관계이다. FN과 FP 가 각각 Type1error, Type2error에 있으므로 Precision과 Recall은 보완적인 관계!
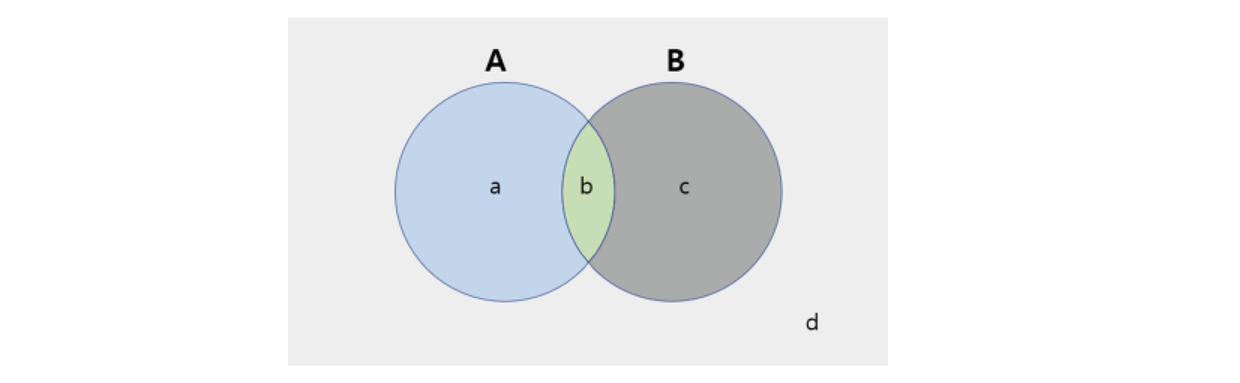
벤다이어그램으로 생각해보기
A영역은 실제 Spam mail
B영역은 모델이 Spam mail로 예측
b : TP(실제로 spam, 모델이 spam으로 예측)
여기서의 precision & recall
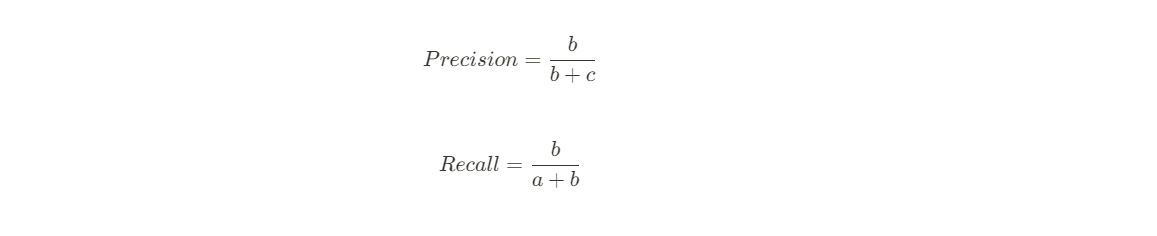
Think about 모델의 입장에서 spam으로만 분류하는 경우 : b+c영역이 확대되는 것이므로 d영역(TN)과 a영역(FN) 감소
→ Recall은 분모인 a가 감소하므로 100%가 됨 (A가 B의 부분집합이 되어버림 = d, a 모두 c에 흡수됨)
→ Precision은 분모가 커져 줄어들게됨
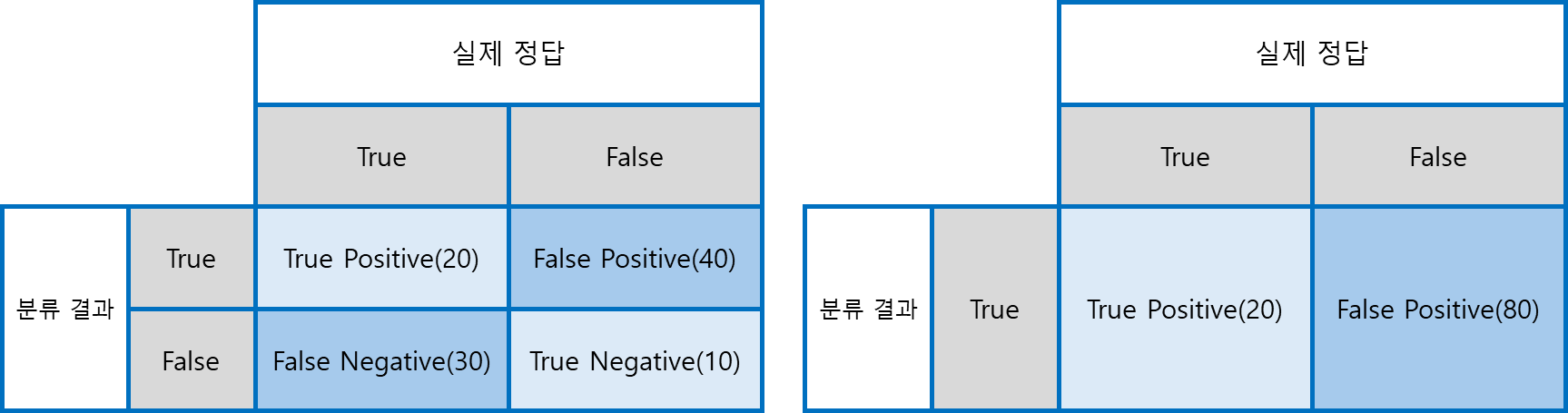
General Case(left)
Recall : 20/(20+30) = 40%, Precision = 20/(20+40) = 33.3%
Only-True Case(right)
Recall : 20/20 = 100%, Precision : 20/(20+80) = 20%
Recall과 Precision을 함께 늘리긴 어려움
Accuracy
위의 내용은 모두 True를 True로 예측한 정답에 대해서만 다루었음. 그러나 False를 False로 예측하는 (TN)도 정답! 이를 고려한 것이 Accuracy

모델의 성능을 가장 intuitive하게 나타낼 수 있음
However, domian bias issue : 특정 부분에 편향된 데이터가 많을 수도(불균형하게 domain이 분포되어있음)
이를 보완한 지표가
F1 Score
Precision과 Recall의 조화평균

산술평균이 아닌 조화평균을 사용한 이유
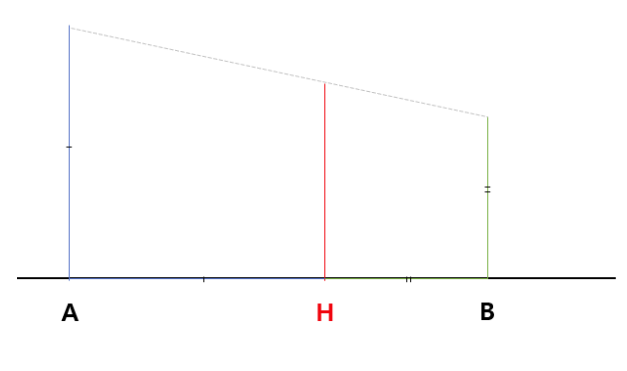
기하적으로 해석했을 때, 선분A와 B를 각각 사다리꼴의 윗변, 아랫변이라 하자. 높이는 A+B이다.
점A에서 길이A만큼 떨어진 거리(=점B에서 길이B만큼 떨어진 거리)에서 맞은편 변에 내린 선분이 조화평균이다.
그림에서 보아도 알 수 있듯 비중이 큰 A에 대해 B보다 멀리 떨어져 있다. 즉, 기존 Accuracy의 문제인 domain bias issue를 해결할 수 있다.
무심코 글을 보다가 수학적인 접근, 원론적인 접근을 하는 것에 감탄하여 공부하고 거의 카피 수준으로 정리해 보았다. 그냥 보고 넘기는 것보단 나을 것 같아서 정리해 보았는데, 확실히 보고 지나칠 때보다 얻어가는 것이 많다.
https://sumniya.tistory.com/26
분류성능평가지표 - Precision(정밀도), Recall(재현율) and Accuracy(정확도)
기계학습에서 모델이나 패턴의 분류 성능 평가에 사용되는 지표들을 다루겠습니다. 어느 모델이든 간에 발전을 위한 feedback은 현재 모델의 performance를 올바르게 평가하는 것에서부터 시작합니
sumniya.tistory.com
'ML\DL' 카테고리의 다른 글
| [ML/DL] - HyperParameter Tuning (240424, 공부기록 11일차) (2) | 2024.04.24 |
|---|---|
| [ML/DL]BO - Bayesian Optimization (240414, 공부기록 4일차) (2) | 2024.04.14 |

