Parameter vs Hyperparameter

Hyperparameter set
튜닝할 수 있는 Hyperparameter의 종류
Example
RandomSearchCV, GridSearchCV
- estimator : estimator object
- param_distributions : dict or list of dicts
- n_iter : int, default=10
- scoring : str, callable, list, tuple or dict, default=None (평가 방법 지정)
- n_jobs : int, default=None (병렬처리 할 개수)
- refit : bool, str, or callable, default=True (최적파라미터를 찾고, 입력된 개체를 해당 파라미터로 재학습)
- cv : int, cross-validation generator or an iterable, default=None (Cross Validation splitting Strategy)
이외
batch_size, epoch, learning_rate, hidden_size, num_layers 등
Hyperparameter Tuning
- Manual Search
- Grid Search
- Random Search
- Bayesian Optimization
- Early Stopping
1. Manual Search
Rules of Thumb. 경험적으로 hyperparameter을 설정하는 방법이다. Naive한 방법이긴 하지만, 이미 성능이 잘 나오는 hyperparameter조합이 알려진 경우가 많기에 따라 하는 경우가 많다.
그러나 Experiment에서, Hyperparameter 조합별 성능을 비교하긴 어렵다.
2. Grid Search

모델에게 hyperparameter별 값을 몇 개 제공해서, 그 조합을 바꾸어 가며 최적 성능을 탐색하는 튜닝방법
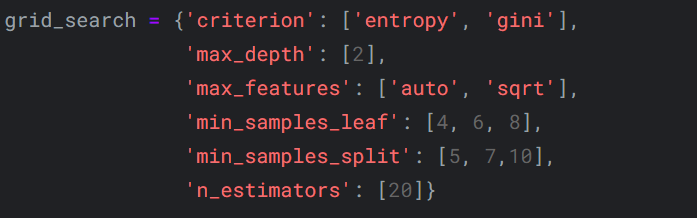
Example
조합1 : {
'criterion' : 'entropy',
'max_depth' : 2,
'max_features' : 'auto',
'min_samples_leaf' : 4,
'min_samples_split' : 5,
'n_estimators' : 20
}
조합2 : {
'criterion' : 'gini',
'max_depth' : 2,
'max_features' : 'sqrt',
'min_samples_leaf' : 4,
'min_samples_split' : 5,
'n_estimators' : 20
}
3. Random Search
주어진 구간 안에서 랜덤으로 숫자를 뽑아 실험 진행
Grid Search에서는 탐색할 hyperparameter들을 지정해주었다면, Random Search에서는 탐색할 구간과 횟수를 지정해줌
Grid Search와 비교했을 때의 장점
Grid Search에서 hyperparameter 'h' : [0.1, 0.2, 0.3, 0.4, 0.5]를 실험해서 'h'가 0.3일 때 최적이었다고 가정
그런데 이건, Grid 안에서의 최적임. 실제 값은 0.278일 수도 있다
→ Grid 안에서만 돌아다니기 보다, random하게 수행하면 더 좋은 성능의 모델을 찾을 확률이 높아진다!
→ Grid를 더 촘촘하게 만들면 안 되나?
탐색범위를 넓히니 더 최적의 성능에 fit할 수 있는 것은 사실
그러나, 2개의 hyperparameter가 각각 2개의 후보를 가지고 있다고 했을 때의 조합은 4가지
이 hyperparameter들의 후보를 10개씩으로 늘리면 조합이 100가지.
hyperparameter의 개수와 그 후보군에 따라 연산횟수가 기하급수적으로 늘어나기 때문에 탐색 횟수가 많아질 수록 Random Search가 오히려 빛을 발함
4. Bayesian Optimization
(이전에 정리한 적이 있지만, High-level에서 다시 공부하며 이해한 내용이 훨씬 많아 블로그를 참조하며 새로 공부했다.
출처 : https://data-scientist-brian-kim.tistory.com/88)
사전정보를 최적값 탐색에 반영하는 것
- 모델 내에서 어떻게 사전정보 학습하고 업데이트하는가?
- Surrogate Model
- 기존 입력값(x1, f(x1)), (x2, f(x2)), ..., (xt, f(xt)) 기반으로 미지의 objective function의 형에 대해 확률적인 추정을 하는 모델
- 수집한 정보를 바탕으로, 어떤 기준으로 다음 탐색값을 찾는가?
- Acquitision function
- Surrogate Model이 목적함수에 대해 추정한 결과 바탕으로 다음번에 탐색할 입력값 후보 추천하는 함수
- 최적값일 가능성이 높은 값 = Surrogate Model에서 함수값이 큰 값
- 아직 Surrogate Model에서의 추정이 불확실한 값 = Surrogate Model에서 표준편차가 큰 값
Surrogate Model
hyperparameter set과 Generalization performance의 관계를 모델링한 모델

이 과정에서 다음 후보로 최적인 hyperparameter 집합을 구해야 함 → Acquitision Function 사용

Acquisition function을 통해 가장 유용한 hyperparameter set 추가, 일반화 성능 다시 계산
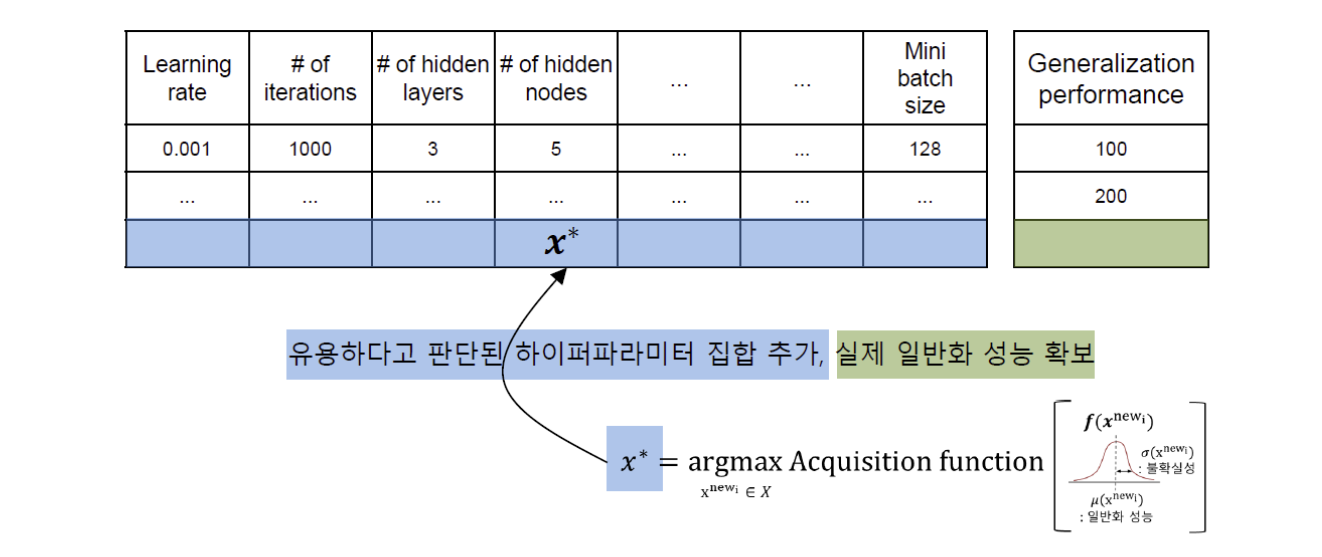
새로 추가된 Set을 기반으로 Surrogate Model을 다시 모델링
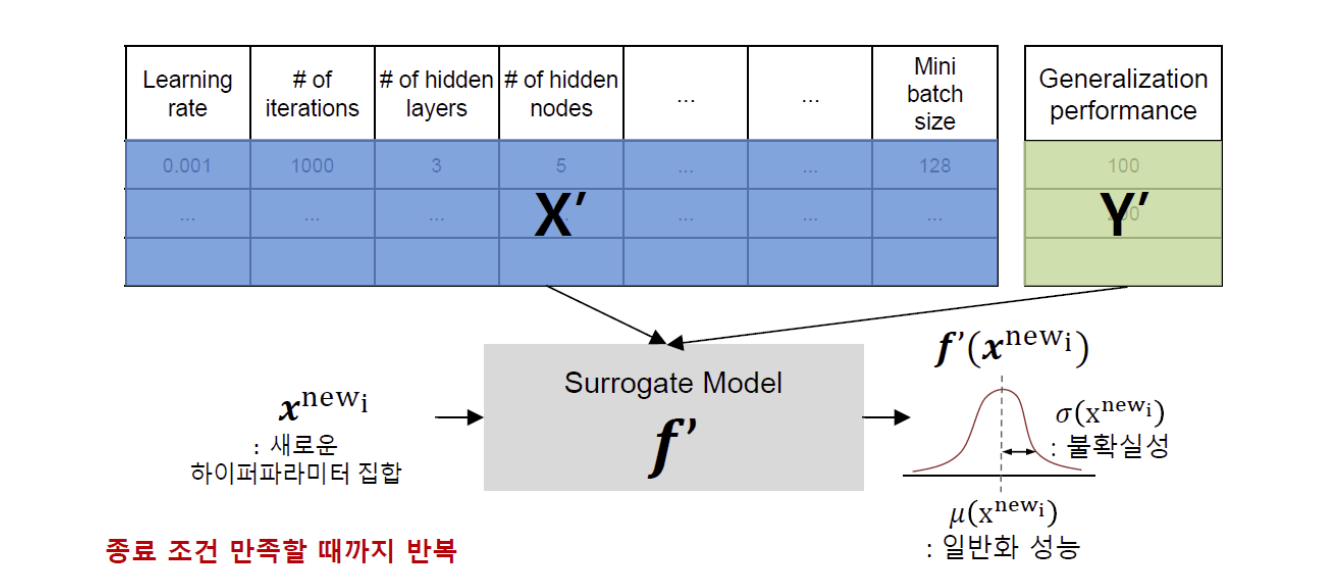

실선 : Actual Objective Function
점선 : Estimated Objective Functin(Surrogate Model)
파란색 영역 : Estimated σ(x)
초록색 영역 : Acqusition Function
[그림으로 다시보는 flow]
t=2
현재의 observation(x)와 새로 찾은 acquisition max
t=3
이전 시점(t=2)에서의 aquisition max가 new observation(x1)
그리고 새로운 acquisition max
t=4
이전 시점(t=3)에서의 acquisition max가 new observation
그리고 또 새로운 acquisition max
.
.
.
종료 조건까지 iteration
5. Early Stopping
모델 훈련 시
너무 많은 epoch → overfitting
너무 적은 epoch → underfitting
Early Stopping : epoch을 과도하게 설저해 두고, "특정 시점"에서 학습을 끝내자!
Example
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping()
model.fit(X_train, Y_train, epoch = 1000, callbacks = [early_stopping])
EarlyStopping(monitor = 'val_loss', min_delta = 0, patience = 0, mode = 'auto')Arguments
- monitor : 학습 조기종료를 위해 모니터링할 항목
- min_delta : 개선되고 있다고 판단하기 위한 최소 변화량(delta). min_delta보다 작을 경우 개선 X로 판단
- patience : 개선 안 된다고 바로 종료하지 말고, 몇 번의 epoch을 눈감아 줄 것인가(참을 것인가)
- mode : 관찰항목(monitor)에 대해 개선이 없다고 판단할 기준
- auto(default) : 자동지정
- min : 관찰값이 감소하기를 멈출 때 (감소하다 증가 / 감소하다 일정)
- max : 관찰값이 증가하기를 멈출 때 (증가하다 감소 / 증가하다 일정)
Reference
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html
https://www.kaggle.com/code/pavansanagapati/automated-hyperparameter-tuning/notebook
https://datarian.io/blog/grid-search-random-search
https://data-scientist-brian-kim.tistory.com/88
'ML\DL' 카테고리의 다른 글
| [ML/DL] 분류성능평가지표 - Precision, Recall, F1-Score (4) | 2024.04.26 |
|---|---|
| [ML/DL]BO - Bayesian Optimization (240414, 공부기록 4일차) (2) | 2024.04.14 |

